
Convolutional neural networks have been widely used as a visual feature extractor mechanism in a diversity of tasks such as image retrieval, object segmentation, object detection, image classification, among others. In fact, after a convolutional network has been trained in a classification context, the internal neural units will have learned to appropriately respond to local relevant information in an input image and we can exploit this behaviour to solve tasks other than classification. To this end, a deep convolutional layer is commonly used as the visual feature extractor.
Although the use of deep convolutional layers as feature extractors (e.g. fc7 in AlexNet or VGG) has shown outstanding performance in a large number of computer vision tasks, there are some circumstances in which this kind of information is not enough to achieve that same level of performance. For instance, when we are dealing with object detection with images containing objects with variable scales. In this case, methods such as Faster-RCNN and YOLO failed when they are in front of small objects. The main problem here is that these methods rely on just one deep convolutional layer as the feature extractor and that layer has undergone a significant loss of resolution due to the pooling layers in the network. Therefore visual information from small regions disappear during convolutional and pooling operations. Thus, this problem demands models capable of dealing with multi-scale information. So, what can we do if multi-scale models are required?. Well, a simple alternative is to train different models using different scales from each training image. Although simple, this approach is very costly. Wait!!, There is another, even better option. We can leverage the hierarchical representation that convolutional neural network learns through their different layers. The next question is how can we do this efficiently?
Resolution vs Semantic
There is trade-off between resolution and depth in convolutional neural networks. In fact, when we go deeper in the network we can find higher-level representations that are associated with higher semantic-level features. This is the main reason why a deeper layer is used as a feature extractor mechanism for different applications. However, deeper layers also are related with loss of resolution due to the underlying pooling layers, which make them inappropriate for dealing with small objects. A picture illustrating the opposite relation between resolution and semantic is shown in Figure 1.
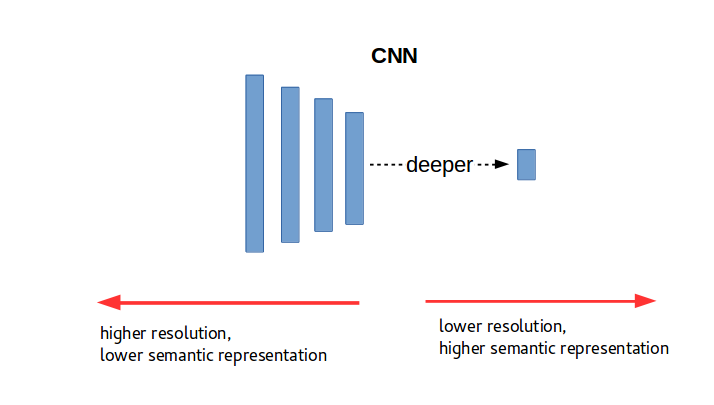
Figure 1. Resolution vs Semantic
With focus on leveraging the internal hierarchical representation of a convolutional neural network, we can construct a multi-scale architecture just by plugging a predictor into each internal layer as in Figure 2. We will call this Case A.
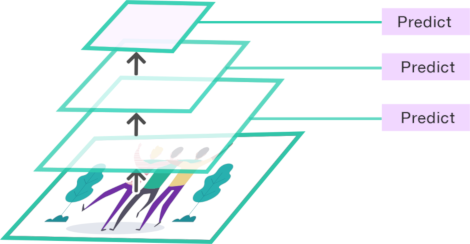
Figure 2. (Case A) Predictors are directly plugged into each convolutional layer.
This solution is very simple, but it presents a critical weakness. There are many predictors relying on shallow layers which provide poor semantic information even though they are high-resolution.
Another architecture is that of the Figure 3 that we will call Case B. In this case, high resolution layers are built from a deeper one. Although it seems that these new layers provide more information that the source layer, it is not the case. Actually, there is nothing new in those resized layers. Thus, if something was lost in the deeper layer, it will remain lost in the resized layers. Therefore the performance of the model using these layers will be similar to that using only the deeper one.
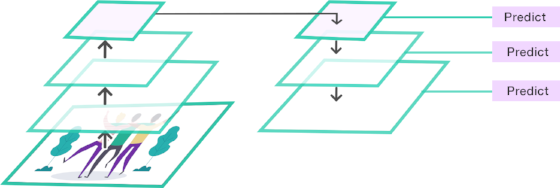
Figure 3. (Case B). Predictors are plugged into resized layers from a deeper one.
To address the drawbacks showed by the previous cases we can produce a multi-scale representation combining higher semantic layers (lower resolution) with higher resolution layers (lower semantic). This proposal although recently described by the Feature Pyramid Network [1], was previously used for Semantic Segmentation [2]. We will call this new architecture Case C (see Figure 4). To this end, Case C works in a similar manner as Case B but the intermediate layers are generated with information obtained from higher resolution layers as shown in Figure 3. This allows us to take the benefits of the two worlds, one with higher resolution (shallow layers) and the other with higher semantic features (deep layers). The combination is carried out as in the ResNet architecture, just by adding the two layers. To make the addition feasible, 1×1 kernel-size convolutional layers are added before the addition using a fixed number of channels (e.g. 256). This proposal has shown outstanding performance in the object detection context overcoming state-of-the-art approaches.
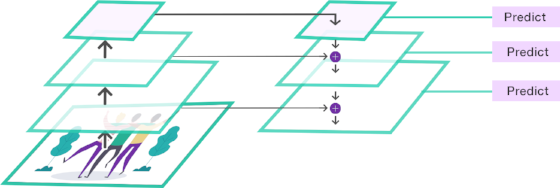
Figure 4. (Case C). Predictors are plugged into layers that combine high resolution with high semantic .
References
[1] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie. Feature Pyramid Networks for Object Detection.
[2] Jonathan Long, Evan Shelhamer, Trevor Darrel. Fully Convolutional Networks for Semantic Segmentation.
